We are users of a cool product from Aternity for application monitoring. The Aternity app runs in the background on our PCs and monitors the end user experience. When a customer says “the system is running slow” we have a wealth of data that can confirm that is the case, quantify how slow, and correlate the slowness with a myriad of other factors (PC model, network segment, OS patches installed, etc.). There are other solutions in this space, including one from Compuware. But, we have been happy with our Aternity investment (a 6 figure expense).
There is a fair amount of setup required to train Aternity how to monitor each application. So, it is not completely magic.
To date we had used this tool to respond to customer complaints and to review monthly performance of our more troublesome applications. But recently our use of application monitoring was taken to the next level by our Field Services group (they support the technologies that our customers touch).
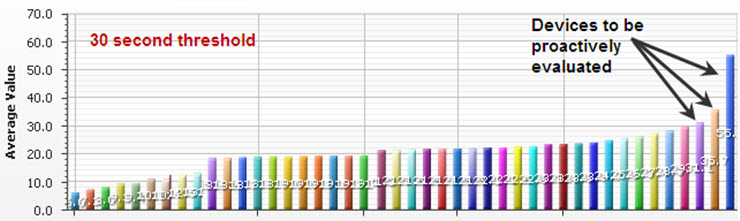
That group is using Aternity as a proactive monitoring tool. They are monitoring three parameters to that serve as an indicator of PC health:
- Boot time
- Blue Screen of Death (BSOD)
- Application launch
When a device encounters a Blue Screen or exceeds a threshold for boot time or application launch it appears on a list. Then, the Field Services team from the appropriate region will replace the device and take the old one back to the device for troubleshooting and re-imaging or disposal.
By being proactive and showing up to replace a device before an incident is reported our Field Services team is creating a “wow” experience for our customers.